
Which experiments and methods were instrumental in generating the critical data which led to its discovery?
There are 4 different kinds of genes which are currently known to be responsible for HNPCC cases. The focus of this web page is the gene hMLH1, which encodes a protein that functions in DNA repair. Two different groups of researchers simultaneously and independently located the gene to a specific place on a specific chromosome, a technique known as "mapping" a gene. The two groups used different approaches to find the gene, although some of the techniques they used were similar. A brief summary of the studies done by each group and a description of the experimental procedures each used follows.
The first group to isolate the hMLH1 gene was Bronner, et al. (Ref. 3), whose report appeared in Nature (368, 258-261), which was published March 17, 1994. Bronner and other researchers knew from previous linkage studies that some unknown gene which was linked to HNPCC transmission was located on chromosome 3p (the short arm of chromosome 3). Additionally, they knew that in families where HNPCC was linked to chromosome 3, the DNA from cancerous tumors often exhibited dinucleotide instability. Dinucleotide instability results from defective DNA proofreading enzymes. These enzymes usually check for mistakes in DNA replication and correct them in order to avoid the possibility of harmful mutations. The first gene isolated as a cause of HNPCC (hMSH2, located on chromosome 2) encodes a DNA mismatch repair enzyme, which is defective in HNPCC patients and also causes dinucleotide instability. Therefore, Bronner, et al., proposed that the unknown gene on chromosome 3 may code for another DNA mismatch repair enzyme. One reason they proposed this hypothesis was that in the bacteria E. coli, there are 3 different genes which code for DNA repair enzymes, and therefore it seemed likely that humans may have more that one of these enzymes.
Bronners research group decided to search the genome for conserved sequences which occur in the DNA repair enzymes. Conserved sequences are specific sequences which are the same, or conserved, across many different organisms. The reason these sequences are conserved is because they code for a structurally and functionally important region of the protein. In their search for a possible gene for the proposed second DNA mismatch repair protein, Bronner, et al., found two conserved sequences in the amino-terminal end of DNA repair enzymes. They made fragments of DNA called primers from these two conserved sequences, and used the primers to screen DNA from human cells. When the primers encounter sequences which are identical or very similar to their own sequences, they are able to make millions of copies of the similar DNA through a technique called PCR (Polymerase Chain Reaction). Thus, PCR amplifies specific fragments of DNA, in this case, a sequence containing the conserved region found in DNA repair enzymes.
Once they had amplified the target DNA and obtained
the DNA sequence, they compared the sequence to the types of bacterial
DNA repair enzymes. They found that one of the bacterial DNA repair
genes shared 41% of its sequence with the fragment they had isolated.
In order to determine whether their isolated clone was located on the short
arm of chromosome 3, they used a technique known as FISH (fluorescence
in situ hybridization).
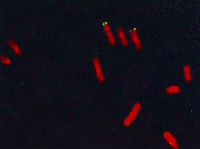 |
In this technique, the chromosomes are spread on a slide, and a fluorescently labeled probe (a fragment of the presumptive gene) is spread on the chromosomes. Then it is washed off, leaving only the probe which is most strongly bound to a specific part of the chromosome. The reason the probe binds strongly is because the sequence of the probe and the sequence of the gene are very similar. Thus, the probe can also be said to bind specifically to the gene which contains a sequence complimentary to the probe. The fluorescent probe gives off color and by staining the chromosomes, the position where the probe binds can be deduced. In this case, the probe bound to a sequence at 3p21-23 (the short arm of chromosome 3, between region 21 and region 23). |
 |
Because they found a gene located on chromosome 3p which shared many similarities to bacterial DNA repair gene, they concluded that the gene they had found was involved in the correction of DNA mispairings, and that it was likely to be the previously unknown gene which had been shown to be linked to HNPCC cases in previous studies. For more information refer to Bronner, et al. (Ref. 3). |
Papadopouloss group began with an idea similar to
Bronners group. They thought that since the first gene linked to
HNPCC encoded a DNA mismatch repair enzyme, maybe there were other enzymes
that did the same thing located on different chromosomes. They began
their search for sequences similar to the known DNA repair enzymes by searching
through many computer databases containing sequences to see if they could
find any human sequences similar to the bacterial repair gene sequences.
They found one which was very similar to a yeast repair gene (yMLH1) and
they termed it hMLH1. In order to find out where the gene was located,
they used a technique called somatic cell hybridization. In this
method, cells of humans and rodents are fused together so that the resulting
cell contains both human and rodent genomes. When these cells are
grown in a lab, human chromosomes are progressively lost on a random basis.
Eventually the cells become stable when only one human chromosome is left
in each cell. Now the researchers were able to design primers (as
in the previous study) for PCR based on the similar portions of the sequence
of the yeast and human genes. PCR will only amplify a very specific
fragment if the complement of the fragment is located in the genome.
The researchers used the somatic cell hybrids to screen each chromosome
separately. Only the cell containing chromosome 3 produced a fragment
with the desired gene. As in Bronners study, Papadopouloss group
used the FISH technique to map the gene to a very precise location, 3p21.
For more information regarding this study, refer to Papadopoulos, et al.,
(Ref. 14).
Although the two groups used different methods and
experimental procedures, both came to the conclusion that the unknown gene
somewhere on chromosome 3 was likely the gene (MLH1) for a DNA mismatch
repair enzyme, which when defective (as in HNPCC families) causes dinucleotide
instability. Both groups mapped the presumptive HNPCC gene to the
short arm of chromosome 3, band 21. Consensus of the two independent
studies presented here is strong evidence that the gene for MLH1 is another
gene which contributes to some cases of Hereditary Non-Polyposis Colon
Cancer.
|
|